
Abstract
Image diffusion models, trained on massive image collections, have emerged as the most versatile image generator model in terms of quality and diversity. They support inverting real images and conditional (e.g., text) generation, making them attractive for high-quality image editing applications. We investigate how to use such pre-trained image models for text-guided video editing. The critical challenge is to achieve the target edits while still preserving the content of the source video. Our method works in two simple steps: first, we use a pre-trained structure-guided (e.g., depth) image diffusion model to perform text-guided edits on an anchor frame; then, in the key step, we progressively propagate the changes to the future frames via self-attention feature injection to adapt the core denoising step of the diffusion model. We then consolidate the changes by adjusting the latent code for the frame before continuing the process. Our approach is training-free and generalizes to a wide range of edits. We demonstrate the effectiveness of the approach by extensive experimentation and compare it against four different prior and parallel efforts (on ). We demonstrate that realistic text-guided video edits are possible, without any compute-intensive preprocessing or video-specific finetuning.
Method Overview
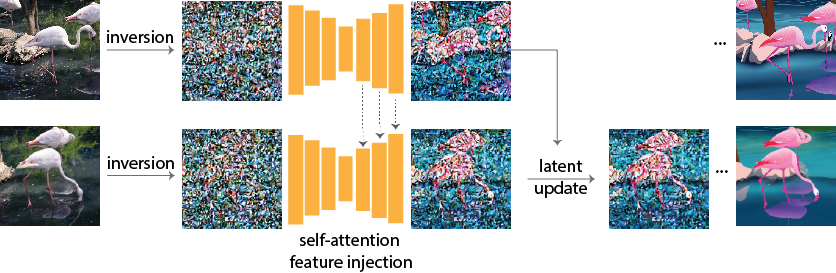
Pix2Video first inverts each frame with DDIM-inversion and consider it as the initial noise for the denoising process. To edit each frame (lower row), we select a reference frame (upper row), inject its self-attention features to the UNet. At each diffusion step, we also update the latent of the current frame guided by the latent of the reference.
Comparison with state-of-the-art approaches method
|
input
|
Jamriska et al.
|
Text2Live
|
|---|---|---|
|
Prompt-to-Prompt
|
Tune-a-Video
|
Pix2Video (ours)
|
|
input
|
Jamriska et al.
|
Text2Live
|
|---|---|---|
|
Prompt-to-Prompt
|
Tune-a-Video
|
Pix2Video (ours)
|
|
input
|
Jamriska et al.
|
Text2Live
|
|---|---|---|
|
Prompt-to-Prompt
|
Tune-a-Video
|
Pix2Video (ours)
|
|
input
|
Jamriska et al.
|
Text2Live
|
|---|---|---|
|
Prompt-to-Prompt
|
Tune-a-Video
|
Pix2Video (ours)
|
Applying Jamriska et al. [20] as post-processing
Our method uses depth as a structural cue which helps to preserve the structure of the input video. Hence, it can be used in conjunction with style propagation methods as a post processing to further improve the results. Specifically, we provide every 3rd frame generated by our method as a keyframe to the method of Jamriska et al. [20] and propagate the style of these keyframes to the inbetween frames.
|
input video
|
ours
|
ours post-processed
|
|---|
|
input video
|
ours
|
ours post-processed
|
|---|
Using Adobe Firefly as the image generator
We have also implemented our method to use Adobe Firefly as the base image generator model and provide results below.
|
input video
|
ours
|
|---|
|
input video
|
ours
|
|---|
More Results
Concurrent work
With the increasing success of large scale text to image generation models in image editing tasks, there has been several parallel efforts that focus on using such models for editing videos. We summarize a few concurrent work that we have recently came across. If we have missed out another key concurrent work, please reach out to us over email. .
Video-P2P extends the idea of null inversion to a video clip and optimizes a common null embedding when inverting the video frames. The authors also adapt a cross attention control mechanism similar to Prompt-to-Prompt. We note that our method is orthogonal and the proposed inversion strategy and cross attention control can be adapted in our method as well. While Video-P2P finetunes the generator given the input video, we do not perform any training.
Fate-Zero also proposes a training-free strategy for editing videos. They focus on utilizing cross attention maps to compute blending masks to minimize inconsistency in the background region of the edited videos.
Tune-A-Video finetunes the image generation model given an input video and uses cross-frame attention for achieving consistent edits. We provide comparisons to this method using the version available at the time of paper preparation.
Gen-1 presents a large scale video generation model that uses depth as a structural cue. The model is trained on a large, mixed dataset of images and videos.